User definable and expandable data processing pipeline
Project Goal
The goal of the project was to build a generic way of processing data. In order to accomplish this I built a system which allows users to chain together nodes which modify incoming data and output the result. Each node effectively represents an operation on data and by chaining multiple nodes together you effectively define the functionality of the data pipeline.
In order to expand the base functionality and add more nodes the relevant APIs for a given language (though only C# is supported right now) need to be implemented and the resulting library dropped into a folder for the main program. This allows anyone to built more nodes so that this can be used todo whatever data processing is needed.
This is where the good part comes in, by using this system one only has to write simple single threaded code. This framework will then parallelize it using both data and task based parallelism. This means that no matter what nodes are combined in which order the system will always execute in a manner that is most efficient and allows for all the data to be processed in the fastest manner.
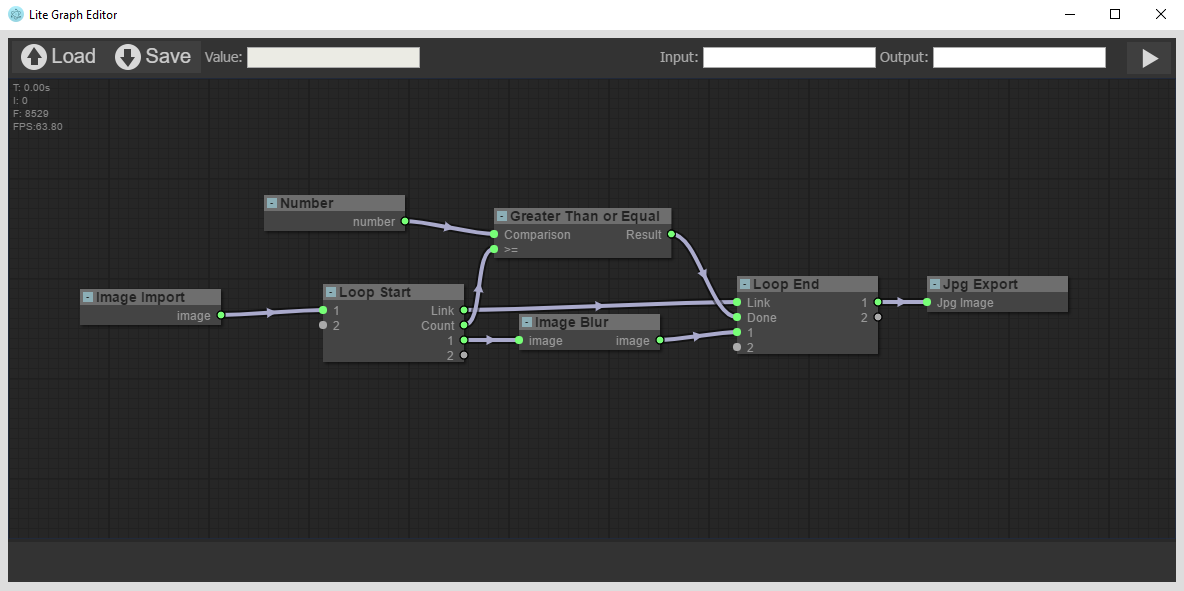
Loops
Once you try to process a problem that requires a lot of repetition in order to get the correct solution it can get very tedious manually copy and pasting nodes until you have the correct amount. To solve this I added loops, these simply execute the nodes between the start and the end until the a flag turns true in the loop end. This however has the limitation that the first node in the loop has to be compatible with the output of the last as the data is from the end is fed back into the start!
Syncing (aggregation)
Some problems require data from multiple input items such as stereoscopic camera calibration where the result of multiple image pairs make up the final calibration result. In this case there is the Sync node which pauses execution and prevents the next nodes being executed until all individual items of data have been processed up to that point. Once this happens all of the results are passed to the next node, I like to think of this as an array of data rather than individual data items.
With this it effectively allows you to vary the total data parallelism throughout processing. If you started with 10 items of data and go into a sync node there is no point processing the result 10 times after the sync node as the results would be identical as it would essentially process the same data 10 times. Instead it processes the data once and allows execution to continue using the single result rather than 10 identical results leading to 10 identical outputs.
Once you fully understand this concept you realize that directly after a sync node more input data can be added as all data after this point is the same. Even data from before the sync node can be connected to nodes after the sync node as this simply adds unique data to the aggregated data from the sync node allowing there to be the same amount of data parallelism after the sync node as before as the total amount of potential outcomes is the same. A similar concept goes for additional inputs as it adds more unique possibilities to the eventual output of the data pipeline.
If your confused about this or just want to know more please feel free to email me or raise an issue on github, I love chatting about how this system works.
Awards
University of Huddersfield Games Showcase 2018
- Winner of "Best Technology In A Game"
- Nominated for "Best Game Programmer"